連線至資料庫
Superset 並未捆綁資料庫的連線功能。將 Superset 連線到資料庫的主要步驟是在您的環境中**安裝正確的資料庫驅動程式**。
您需要為您想要用作中繼資料資料庫的資料庫安裝所需的套件,以及連線到您想要透過 Superset 存取的資料庫所需的套件。有關設定 Superset 中繼資料資料庫的資訊,請參閱安裝文件 (Docker Compose、Kubernetes)
本文件嘗試保留指向常用資料庫引擎的不同驅動程式的指標。
安裝資料庫驅動程式
Superset 需要為您想要連線的每個資料庫引擎安裝 Python DB-API 資料庫驅動程式和 SQLAlchemy 方言。
您可以在這裡閱讀更多關於如何將新的資料庫驅動程式安裝到您的 Superset 設定中的資訊。
支援的資料庫和相依性
以下顯示了一些建議的套件。請參考 pyproject.toml 以取得與 Superset 相容的版本。
資料庫 | PyPI 套件 | 連線字串 |
|---|---|---|
| AWS Athena | pip install pyathena[pandas] , pip install PyAthenaJDBC | awsathena+rest://{access_key_id}:{access_key}@athena.{region}.amazonaws.com/{schema}?s3_staging_dir={s3_staging_dir}&... |
| AWS DynamoDB | pip install pydynamodb | dynamodb://{access_key_id}:{secret_access_key}@dynamodb.{region_name}.amazonaws.com?connector=superset |
| AWS Redshift | pip install sqlalchemy-redshift | redshift+psycopg2://<userName>:<DBPassword>@<AWS 端點>:5439/<資料庫名稱> |
| Apache Doris | pip install pydoris | doris://<使用者>:<密碼>@<主機>:<連接埠>/<目錄>.<資料庫> |
| Apache Drill | pip install sqlalchemy-drill | drill+sadrill:// 用於 JDBC drill+jdbc:// |
| Apache Druid | pip install pydruid | druid://<使用者>:<密碼>@<主機>:<連接埠-預設為 9088>/druid/v2/sql |
| Apache Hive | pip install pyhive | hive://hive@{hostname}:{port}/{database} |
| Apache Impala | pip install impyla | impala://{hostname}:{port}/{database} |
| Apache Kylin | pip install kylinpy | kylin://<使用者名稱>:<密碼>@<主機名稱>:<連接埠>/<專案>?<參數 1>=<值 1>&<參數 2>=<值 2> |
| Apache Pinot | pip install pinotdb | pinot://BROKER:5436/query?server=http://CONTROLLER:5983/ |
| Apache Solr | pip install sqlalchemy-solr | solr://{username}:{password}@{hostname}:{port}/{server_path}/{collection} |
| Apache Spark SQL | pip install pyhive | hive://hive@{hostname}:{port}/{database} |
| Ascend.io | pip install impyla | ascend://{username}:{password}@{hostname}:{port}/{database}?auth_mechanism=PLAIN;use_ssl=true |
| Azure MS SQL | pip install pymssql | mssql+pymssql://UserName@presetSQL:TestPassword@presetSQL.database.windows.net:1433/TestSchema |
| ClickHouse | pip install clickhouse-connect | clickhousedb://{username}:{password}@{hostname}:{port}/{database} |
| CockroachDB | pip install cockroachdb | cockroachdb://root@{hostname}:{port}/{database}?sslmode=disable |
| Couchbase | pip install couchbase-sqlalchemy | couchbase://{username}:{password}@{hostname}:{port}?truststorepath={ssl 憑證路徑} |
| Denodo | pip install denodo-sqlalchemy | denodo://{username}:{password}@{hostname}:{port}/{database} |
| Dremio | pip install sqlalchemy_dremio | dremio+flight://{username}:{password}@{host}:32010,通常很有用:?UseEncryption=true/false。對於舊版 ODBC:dremio+pyodbc://{username}:{password}@{host}:31010 |
| Elasticsearch | pip install elasticsearch-dbapi | elasticsearch+http://{user}:{password}@{host}:9200/ |
| Exasol | pip install sqlalchemy-exasol | exa+pyodbc://{username}:{password}@{hostname}:{port}/my_schema?CONNECTIONLCALL=en_US.UTF-8&driver=EXAODBC |
| Google BigQuery | pip install sqlalchemy-bigquery | bigquery://{project_id} |
| Google Sheets | pip install shillelagh[gsheetsapi] | gsheets:// |
| Firebolt | pip install firebolt-sqlalchemy | firebolt://{client_id}:{client_secret}@{database}/{engine_name}?account_name={name} |
| Hologres | pip install psycopg2 | postgresql+psycopg2://<使用者名稱>:<資料庫密碼>@<資料庫主機>/<資料庫名稱> |
| IBM Db2 | pip install ibm_db_sa | db2+ibm_db:// |
| IBM Netezza Performance Server | pip install nzalchemy | netezza+nzpy://<使用者名稱>:<資料庫密碼>@<資料庫主機>/<資料庫名稱> |
| MySQL | pip install mysqlclient | mysql://<使用者名稱>:<資料庫密碼>@<資料庫主機>/<資料庫名稱> |
| OceanBase | pip install oceanbase_py | oceanbase://<使用者名稱>:<資料庫密碼>@<資料庫主機>/<資料庫名稱> |
| Oracle | pip install cx_Oracle | oracle:// |
| PostgreSQL | pip install psycopg2 | postgresql://<使用者名稱>:<資料庫密碼>@<資料庫主機>/<資料庫名稱> |
| Presto | pip install pyhive | presto:// |
| Rockset | pip install rockset-sqlalchemy | rockset://<api_key>:@<api_server> |
| SAP Hana | pip install hdbcli sqlalchemy-hana 或 pip install apache-superset[hana] | hana://{username}:{password}@{host}:{port} |
| StarRocks | pip install starrocks | starrocks://<使用者>:<密碼>@<主機>:<連接埠>/<目錄>.<資料庫> |
| Snowflake | pip install snowflake-sqlalchemy | snowflake://{user}:{password}@{account}.{region}/{database}?role={role}&warehouse={warehouse} |
| SQLite | 無需額外程式庫 | sqlite://path/to/file.db?check_same_thread=false |
| SQL Server | pip install pymssql | mssql+pymssql:// |
| Teradata | pip install teradatasqlalchemy | teradatasql://{user}:{password}@{host} |
| TimescaleDB | pip install psycopg2 | postgresql://<使用者名稱>:<資料庫密碼>@<資料庫主機>:<連接埠>/<資料庫名稱> |
| Trino | pip install trino | trino://{username}:{password}@{hostname}:{port}/{catalog} |
| Vertica | pip install sqlalchemy-vertica-python | vertica+vertica_python://<使用者名稱>:<資料庫密碼>@<資料庫主機>/<資料庫名稱> |
| YugabyteDB | pip install psycopg2 | postgresql://<使用者名稱>:<資料庫密碼>@<資料庫主機>/<資料庫名稱> |
請注意,還支援許多其他資料庫,主要標準是是否存在可運作的 SQLAlchemy 方言和 Python 驅動程式。搜尋關鍵字「sqlalchemy + (資料庫名稱)」應該可以幫助您找到正確的位置。
如果您的資料庫或資料引擎不在清單上,但存在 SQL 介面,請在 Superset GitHub 存放庫中提交問題,以便我們可以著手記錄和支援它。
如果您想為 Superset 整合建置資料庫連接器,請閱讀下列教學。
在 Docker 映像中安裝驅動程式
Superset 需要為您想要連線的每個其他資料庫類型安裝 Python 資料庫驅動程式。
在本範例中,我們將逐步說明如何安裝 MySQL 連接器程式庫。連接器程式庫的安裝過程對於所有其他程式庫都是相同的。
1. 確定您需要的驅動程式
查閱資料庫驅動程式清單,並找出連線到您的資料庫所需的 PyPI 套件。在本範例中,我們正在連線到 MySQL 資料庫,因此我們需要 mysqlclient 連接器程式庫。
2. 在容器中安裝驅動程式
我們需要將 mysqlclient 程式庫安裝到 Superset Docker 容器中 (是否安裝在主機上並不重要)。我們可以透過 docker exec -it <container_name> bash 進入正在執行的容器,並在那裡執行 pip install mysqlclient,但這樣不會永久保存。
為了解決這個問題,Superset docker compose 部署使用了 requirements-local.txt 檔案的慣例。此檔案中列出的所有套件都會在執行時從 PyPI 安裝到容器中。為了本地開發的目的,Git 將忽略此檔案。
在與您的 docker-compose.yml 或 docker-compose-non-dev.yml 檔案位於同一個目錄中的名為 docker 的子目錄中建立檔案 requirements-local.txt。
# Run from the repo root:
touch ./docker/requirements-local.txt
加入以上步驟中識別的驅動程式。您可以使用文字編輯器,或從命令列執行,如下所示:
echo "mysqlclient" >> ./docker/requirements-local.txt
如果您執行的是預設(非客製化)的 Superset 映像檔,則您已完成。使用 docker compose -f docker-compose-non-dev.yml up 啟動 Superset,驅動程式應已存在。
您可以透過執行 docker exec -it <container_name> bash 進入正在執行的容器,並執行 pip freeze 來檢查其是否存在。PyPI 套件應存在於列印的清單中。
如果您執行的是客製化的 Docker 映像檔,請重建您的本機映像檔,並將新的驅動程式包含在其中。
docker compose build --force-rm
Docker 映像檔重建完成後,執行 docker compose up 重新啟動 Superset。
3. 連線至 MySQL
現在您已在容器中安裝了 MySQL 驅動程式,您應該可以透過 Superset 網頁 UI 連線至您的資料庫。
以管理員身分,前往「設定」->「資料:資料庫連線」,然後按一下「+資料庫」按鈕。從那裡,依照使用資料庫連線 UI 頁面上的步驟操作。
請參閱 Superset 文件中針對您特定資料庫類型的頁面,以判斷連線字串和您需要輸入的任何其他參數。例如,在MySQL 頁面上,我們看到連線到本機 MySQL 資料庫的連線字串會因設定是在 Linux 或 Mac 上執行而有所不同。
按一下「測試連線」按鈕,應該會出現彈出訊息,顯示「連線看起來沒問題!」。
4. 疑難排解
如果測試失敗,請檢閱您的 Docker 記錄檔以查看錯誤訊息。Superset 使用 SQLAlchemy 連線至資料庫;若要針對您的資料庫連線字串進行疑難排解,您可以從 Superset 應用程式容器或主機環境中啟動 Python,並嘗試直接連線至所需的資料庫並擷取資料。這樣做的目的是排除 Superset 的影響,以便隔離問題。
針對您要 Superset 連線的每種資料庫類型,重複此程序。
特定資料庫的說明
Ascend.io
建議用於 Ascend.io 的連接器程式庫是 impyla。
預期的連線字串格式如下
ascend://{username}:{password}@{hostname}:{port}/{database}?auth_mechanism=PLAIN;use_ssl=true
Apache Doris
sqlalchemy-doris 程式庫是透過 SQLAlchemy 連線至 Apache Doris 的建議方式。
您需要下列設定值才能組成連線字串
- 使用者:使用者名稱
- 密碼:密碼
- 主機:Doris FE 主機
- 連接埠:Doris FE 連接埠
- 目錄:目錄名稱
- 資料庫:資料庫名稱
以下是連線字串的樣子
doris://<User>:<Password>@<Host>:<Port>/<Catalog>.<Database>
AWS Athena
PyAthenaJDBC
PyAthenaJDBC 是 Amazon Athena JDBC 驅動程式的 Python DB 2.0 相容包裝器。
Amazon Athena 的連線字串如下
awsathena+jdbc://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com/{schema_name}?s3_staging_dir={s3_staging_dir}&...
請注意,您需要在形成連線字串時逸出並編碼,如下所示
s3://... -> s3%3A//...
PyAthena
您也可以使用 PyAthena 程式庫(不需要 Java),搭配下列連線字串
awsathena+rest://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com/{schema_name}?s3_staging_dir={s3_staging_dir}&...
PyAthena 程式庫也允許假設特定的 IAM 角色,您可以在 Superset 的 Athena 資料庫連線 UI 中,「進階」-->「其他」-->「引擎參數」底下定義該角色。
{
"connect_args": {
"role_arn": "<role arn>"
}
}
AWS DynamoDB
PyDynamoDB
PyDynamoDB 是 Amazon DynamoDB 的 Python DB API 2.0 (PEP 249) 用戶端。
Amazon DynamoDB 的連線字串如下
dynamodb://{aws_access_key_id}:{aws_secret_access_key}@dynamodb.{region_name}.amazonaws.com:443?connector=superset
如需更多文件,請造訪:PyDynamoDB WIKI。
AWS Redshift
sqlalchemy-redshift 程式庫是透過 SQLAlchemy 連線至 Redshift 的建議方式。
此方言需要 redshift_connector 或 psycopg2 才能正常運作。
您需要設定下列值才能組成連線字串
- 使用者名稱:userName
- 密碼:DBPassword
- 資料庫主機:AWS 端點
- 資料庫名稱:資料庫名稱
- 連接埠:預設為 5439
psycopg2
以下是 SQLALCHEMY URI 的樣子
redshift+psycopg2://<userName>:<DBPassword>@<AWS End Point>:5439/<Database Name>
redshift_connector
以下是 SQLALCHEMY URI 的樣子
redshift+redshift_connector://<userName>:<DBPassword>@<AWS End Point>:5439/<Database Name>
使用以 IAM 為基礎的憑證與 Redshift 叢集:
Amazon Redshift 叢集也支援產生以 IAM 為基礎的臨時資料庫使用者憑證。
您的 Superset 應用程式的 IAM 角色應具有權限,才能呼叫 redshift:GetClusterCredentials 作業。
您必須在 Superset 的 Redshift 資料庫連線 UI 中,「進階」-->「其他」-->「引擎參數」底下定義下列引數。
{"connect_args":{"iam":true,"database":"<database>","cluster_identifier":"<cluster_identifier>","db_user":"<db_user>"}}
且 SQLALCHEMY URI 應設定為 redshift+redshift_connector://
使用以 IAM 為基礎的憑證與 Redshift 無伺服器:
Redshift 無伺服器支援使用 IAM 角色連線。
您的 Superset 應用程式的 IAM 角色應在 Redshift 無伺服器工作群組上具有 redshift-serverless:GetCredentials 和 redshift-serverless:GetWorkgroup 權限。
您必須在 Superset 的 Redshift 資料庫連線 UI 中,「進階」-->「其他」-->「引擎參數」底下定義下列引數。
{"connect_args":{"iam":true,"is_serverless":true,"serverless_acct_id":"<aws account number>","serverless_work_group":"<redshift work group>","database":"<database>","user":"IAMR:<superset iam role name>"}}
ClickHouse
若要在 Superset 中使用 ClickHouse,您需要安裝 clickhouse-connect Python 程式庫。
如果使用 Docker Compose 執行 Superset,請將下列項目新增至您的 ./docker/requirements-local.txt 檔案
clickhouse-connect>=0.6.8
建議用於 ClickHouse 的連接器程式庫是 clickhouse-connect。
預期的連線字串格式如下
clickhousedb://<user>:<password>@<host>:<port>/<database>[?options…]clickhouse://{username}:{password}@{hostname}:{port}/{database}
以下是一個實際連線字串的具體範例
clickhousedb://demo:demo@github.demo.trial.altinity.cloud/default?secure=true
如果您在本機電腦上使用 Clickhouse,可以使用使用預設使用者且沒有密碼的 http 通訊協定 URL(並且不會加密連線)。
clickhousedb://localhost/default
CockroachDB
建議用於 CockroachDB 的連接器程式庫是 sqlalchemy-cockroachdb。
預期的連線字串格式如下
cockroachdb://root@{hostname}:{port}/{database}?sslmode=disable
Couchbase
Couchbase 的 Superset 連線旨在支援兩種服務:Couchbase Analytics 和 Couchbase Columnar。建議用於 Couchbase 的連接器程式庫是 couchbase-sqlalchemy。
pip install couchbase-sqlalchemy
預期的連線字串格式如下
couchbase://{username}:{password}@{hostname}:{port}?truststorepath={certificate path}?ssl={true/false}
CrateDB
建議用於 CrateDB 的連接器程式庫是 crate。您也需要為此程式庫安裝額外內容。我們建議將如下所示的文字新增至您的需求檔案
crate[sqlalchemy]==0.26.0
預期的連線字串格式如下
crate://crate@127.0.0.1:4200
Databend
建議用於 Databend 的連接器程式庫是 databend-sqlalchemy。Superset 已在 databend-sqlalchemy>=0.2.3 上測試過。
建議的連線字串為
databend://{username}:{password}@{host}:{port}/{database_name}
以下是 Superset 連線至 Databend 資料庫的連線字串範例
databend://user:password@localhost:8000/default?secure=false
Databricks
Databricks 現在提供原生 DB API 2.0 驅動程式 databricks-sql-connector,該驅動程式可與 sqlalchemy-databricks 方言搭配使用。您可以使用下列命令安裝兩者
pip install "apache-superset[databricks]"
若要使用 Hive 連接器,您需要叢集的下列資訊
- 伺服器主機名稱
- 連接埠
- HTTP 路徑
這些資訊可以在「設定」->「進階選項」->「JDBC/ODBC」底下找到。
您也需要從「設定」->「使用者設定」->「存取權杖」取得存取權杖。
取得所有資訊後,新增一個類型為「Databricks 原生連接器」的資料庫,並使用下列 SQLAlchemy URI
databricks+connector://token:{access_token}@{server_hostname}:{port}/{database_name}
您也需要在「其他」->「引擎參數」中新增下列組態,並加上您的 HTTP 路徑
{
"connect_args": {"http_path": "sql/protocolv1/o/****"}
}
舊版驅動程式
Superset 最初使用 databricks-dbapi 連線至 Databricks。如果您的官方 Databricks 連接器有問題,您可以嘗試使用此連接器
pip install "databricks-dbapi[sqlalchemy]"
當使用 databricks-dbapi 時,有兩種方式可以連線至 Databricks:使用 Hive 連接器或 ODBC 連接器。兩種方式的運作方式類似,但只有 ODBC 可以用於連線至 SQL 端點。
Hive
若要連線至 Hive 叢集,請在 Superset 中新增一個類型為「Databricks 互動式叢集」的資料庫,並使用下列 SQLAlchemy URI
databricks+pyhive://token:{access_token}@{server_hostname}:{port}/{database_name}
您也需要在「其他」->「引擎參數」中新增下列組態,並加上您的 HTTP 路徑
{"connect_args": {"http_path": "sql/protocolv1/o/****"}}
ODBC
對於 ODBC,您首先需要安裝適用於您平台的 ODBC 驅動程式。
對於一般連線,請在為資料庫選擇「Databricks互動式叢集」或「Databricks SQL 端點」之後,根據您的使用情況使用此作為 SQLAlchemy URI。
databricks+pyodbc://token:{access_token}@{server_hostname}:{port}/{database_name}
以及連線引數。
{"connect_args": {"http_path": "sql/protocolv1/o/****", "driver_path": "/path/to/odbc/driver"}}
驅動程式路徑應為
/Library/simba/spark/lib/libsparkodbc_sbu.dylib(Mac OS)/opt/simba/spark/lib/64/libsparkodbc_sb64.so(Linux)
若要連線至 SQL 端點,您需要使用端點的 HTTP 路徑。
{"connect_args": {"http_path": "/sql/1.0/endpoints/****", "driver_path": "/path/to/odbc/driver"}}
Denodo
針對 Denodo 建議使用的連接器函式庫為 denodo-sqlalchemy。
預期的連線字串格式如下 (預設連接埠為 9996)
denodo://{username}:{password}@{hostname}:{port}/{database}
Dremio
針對 Dremio 建議使用的連接器函式庫為 sqlalchemy_dremio。
ODBC 的預期連線字串格式如下 (預設連接埠為 31010)
dremio+pyodbc://{username}:{password}@{host}:{port}/{database_name}/dremio?SSL=1
Arrow Flight 的預期連線字串格式如下 (Dremio 4.9.1+。預設連接埠為 32010)
dremio+flight://{username}:{password}@{host}:{port}/dremio
這篇 Dremio 的部落格文章 有一些關於將 Superset 連接到 Dremio 的額外實用說明。
Apache Drill
SQLAlchemy
連線到 Apache Drill 的建議方式是透過 SQLAlchemy。您可以使用 sqlalchemy-drill 套件。
完成之後,您可以使用兩種方式連線到 Drill,透過 REST 介面或透過 JDBC。如果您透過 JDBC 連線,您必須安裝 Drill JDBC 驅動程式。
Drill 的基本連線字串如下所示
drill+sadrill://<username>:<password>@<host>:<port>/<storage_plugin>?use_ssl=True
若要連線到在本機以內嵌模式執行的 Drill,您可以使用下列連線字串
drill+sadrill://localhost:8047/dfs?use_ssl=False
JDBC
透過 JDBC 連線到 Drill 比較複雜,我們建議您依照本教學課程。
連線字串如下所示
drill+jdbc://<username>:<password>@<host>:<port>
ODBC
我們建議您閱讀 Apache Drill 文件並閱讀 GitHub README,以了解如何透過 ODBC 使用 Drill。
Apache Druid
Superset 隨附 Druid 的原生連接器(在 DRUID_IS_ACTIVE 旗標後方),但此連線器正逐漸被淘汰,轉而採用 pydruid 函式庫中提供的 SQLAlchemy / DBAPI 連接器。
連線字串如下所示
druid://<User>:<password>@<Host>:<Port-default-9088>/druid/v2/sql
以下是此連線字串的關鍵元件分解
User:連線至資料庫所需的認證的使用者名稱部分Password:連線至資料庫所需的認證的密碼部分Host:執行資料庫的主機的 IP 位址 (或 URL)Port:資料庫執行所在的主機上公開的特定連接埠
自訂 Druid 連線
新增 Druid 連線時,您可以使用「新增資料庫」表單中的幾種不同方式自訂連線。
自訂憑證
在設定 Druid 的新資料庫連線時,您可以在「根憑證」欄位中新增憑證。

使用自訂憑證時,pydruid 會自動使用 https 配置。
停用 SSL 驗證
若要停用 SSL 驗證,請將以下內容新增至「其他」欄位
engine_params:
{"connect_args":
{"scheme": "https", "ssl_verify_cert": false}}
彙總
可以在 Superset 中定義和使用常見的彙總或 Druid 指標。第一個且較簡單的使用案例是使用資料來源的編輯檢視中公開的核取方塊矩陣 (「來源 -> Druid 資料來源 -> [您的資料來源] -> 編輯 -> [索引標籤] 列出 Druid 資料行」)。
按一下 GroupBy 和 Filterable 核取方塊將會使資料行出現在「探索」檢視中的相關下拉式清單中。勾選「計算不同值」、「最小值」、「最大值」或「總和」將會產生新的指標,這些指標會在儲存資料來源時出現在「列出 Druid 指標」索引標籤中。
透過編輯這些指標,您會注意到其 JSON 元素對應於 Druid 彙總定義。您可以依照 Druid 文件,從「列出 Druid 指標」索引標籤手動建立自己的彙總。
後彙總
Druid 支援後彙總,這在 Superset 中也適用。您只需要建立一個指標,就像您手動建立彙總一樣,但指定 postagg 作為「指標類型」。然後,您必須在 JSON 欄位中提供有效的 json 後彙總定義 (如 Druid 文件中所指定)。
Elasticsearch
針對 Elasticsearch 建議使用的連接器函式庫為 elasticsearch-dbapi。
Elasticsearch 的連線字串如下所示
elasticsearch+http://{user}:{password}@{host}:9200/
使用 HTTPS
elasticsearch+https://{user}:{password}@{host}:9200/
Elasticsearch 的預設限制為 10000 列,因此您可以在叢集上增加此限制,或在設定中設定 Superset 的列限制。
ROW_LIMIT = 10000
例如,您可以在 SQL Lab 上查詢多個索引
SELECT timestamp, agent FROM "logstash"
但是,若要使用多個索引的可視化效果,您需要在叢集上建立別名索引
POST /_aliases
{
"actions" : [
{ "add" : { "index" : "logstash-**", "alias" : "logstash_all" } }
]
}
然後使用別名 logstash_all 註冊您的資料表
時區
預設情況下,Superset 會將 UTC 時區用於 elasticsearch 查詢。如果您需要指定時區,請編輯您的資料庫,並在「其他 > 引擎參數」中輸入您指定時區的設定。
{
"connect_args": {
"time_zone": "Asia/Shanghai"
}
}
關於時區問題,另一個要注意的問題是,在 elasticsearch7.8 之前,如果您想要將字串轉換為 DATETIME 物件,您需要使用 CAST 函數,但此函數不支援我們的 time_zone 設定。因此,建議升級至 elasticsearch7.8 之後的版本。在 elasticsearch7.8 之後,您可以使用 DATETIME_PARSE 函數來解決此問題。DATETIME_PARSE 函數是為了支援我們的 time_zone 設定,在這裡您需要在「其他 > 版本」設定中填入您的 elasticsearch 版本號碼。superset 將會使用 DATETIME_PARSE 函數進行轉換。
停用 SSL 驗證
若要停用 SSL 驗證,請將以下內容新增至「SQLALCHEMY URI」欄位
elasticsearch+https://{user}:{password}@{host}:9200/?verify_certs=False
Exasol
針對 Exasol 建議使用的連接器函式庫為 sqlalchemy-exasol。
Exasol 的連線字串如下所示
exa+pyodbc://{username}:{password}@{hostname}:{port}/my_schema?CONNECTIONLCALL=en_US.UTF-8&driver=EXAODBC
Firebird
針對 Firebird 建議使用的連接器函式庫為 sqlalchemy-firebird。Superset 已在 sqlalchemy-firebird>=0.7.0, <0.8 上測試過。
建議的連線字串為
firebird+fdb://{username}:{password}@{host}:{port}//{path_to_db_file}
以下是 Superset 連接到本機 Firebird 資料庫的連線字串範例
firebird+fdb://SYSDBA:masterkey@192.168.86.38:3050//Library/Frameworks/Firebird.framework/Versions/A/Resources/examples/empbuild/employee.fdb
Firebolt
針對 Firebolt 建議使用的連接器函式庫為 firebolt-sqlalchemy。
建議的連線字串為
firebolt://{username}:{password}@{database}?account_name={name}
or
firebolt://{username}:{password}@{database}/{engine_name}?account_name={name}
也可以使用服務帳戶進行連線
firebolt://{client_id}:{client_secret}@{database}?account_name={name}
or
firebolt://{client_id}:{client_secret}@{database}/{engine_name}?account_name={name}
Google BigQuery
針對 BigQuery 建議使用的連接器函式庫為 sqlalchemy-bigquery。
安裝 BigQuery 驅動程式
請按照 此處 的步驟,了解在透過 docker compose 在本機設定 Superset 時,如何安裝新的資料庫驅動程式。
echo "sqlalchemy-bigquery" >> ./docker/requirements-local.txt
連線到 BigQuery
在 Superset 中新增 BigQuery 連線時,您需要新增 GCP 服務帳戶認證檔案 (以 JSON 格式)。
- 透過 Google Cloud Platform 控制面板建立您的服務帳戶,授予其存取適當 BigQuery 資料集的權限,並下載服務帳戶的 JSON 組態檔。
- 在 Superset 中,您可以上傳該 JSON 或以以下格式新增 JSON Blob (這應為您的認證 JSON 檔案的內容)
{
"type": "service_account",
"project_id": "...",
"private_key_id": "...",
"private_key": "...",
"client_email": "...",
"client_id": "...",
"auth_uri": "...",
"token_uri": "...",
"auth_provider_x509_cert_url": "...",
"client_x509_cert_url": "..."
}
-
此外,也可以透過 SQLAlchemy URI 連線
BigQuery 的連線字串如下所示
bigquery://{project_id}移至「進階」索引標籤,以以下格式將 JSON Blob 新增至資料庫組態表單中的「安全額外」欄位
{
"credentials_info": <contents of credentials JSON file>
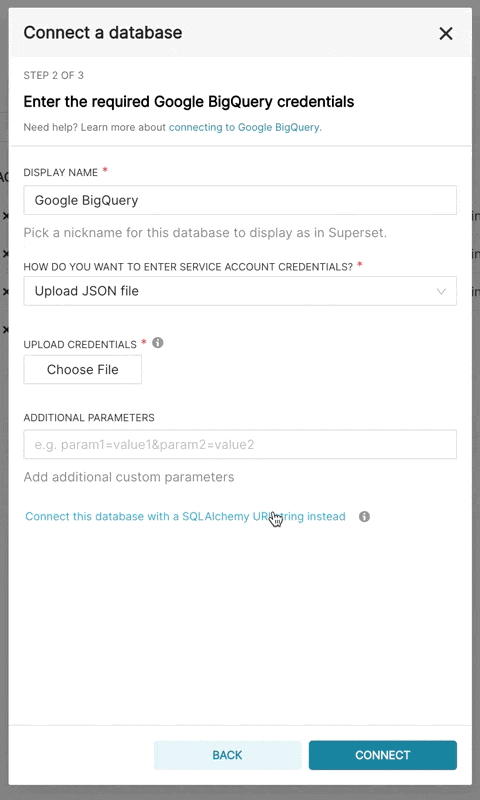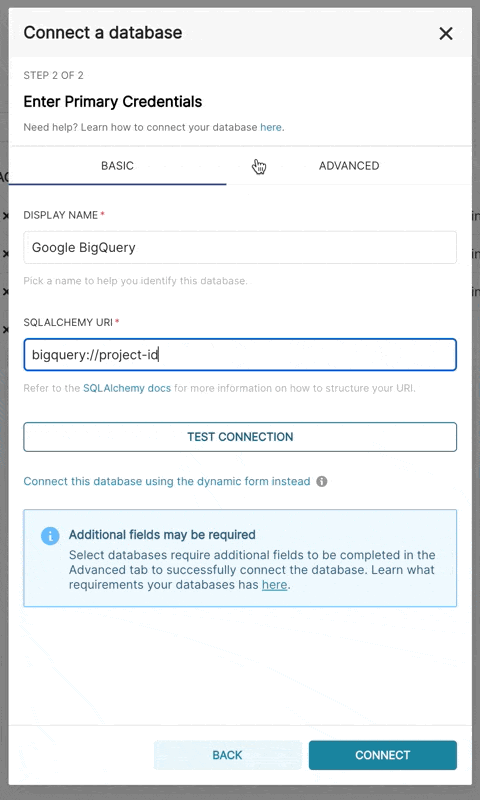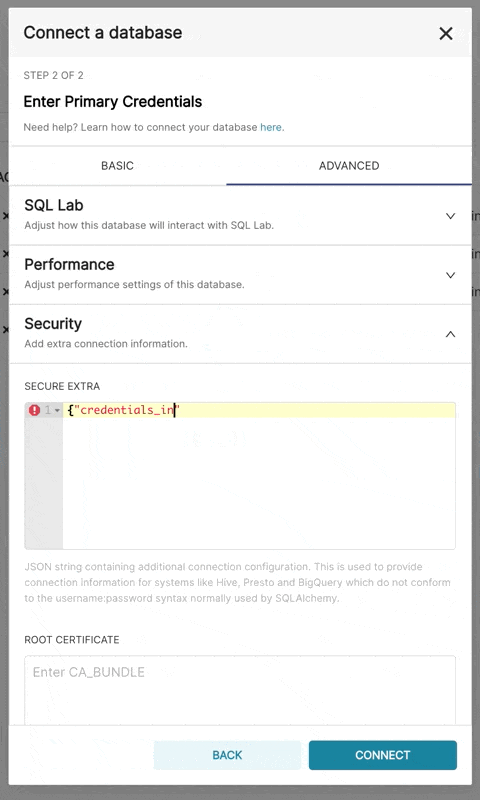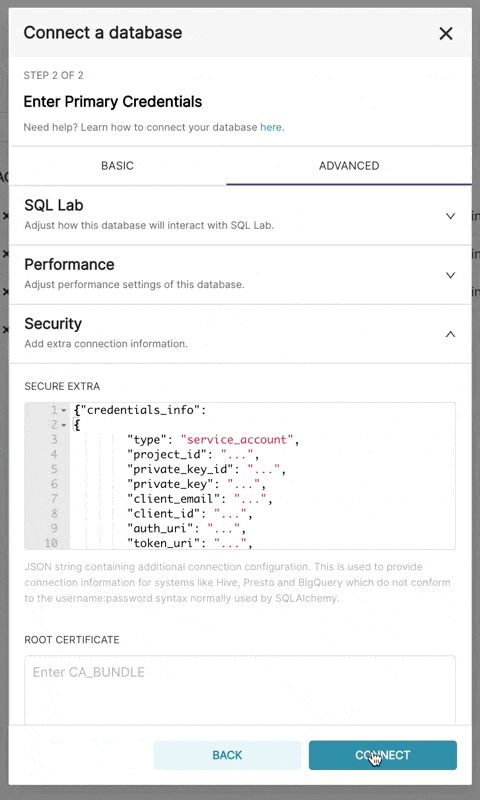
}產生的檔案應具有此結構
{
"credentials_info": {
"type": "service_account",
"project_id": "...",
"private_key_id": "...",
"private_key": "...",
"client_email": "...",
"client_id": "...",
"auth_uri": "...",
"token_uri": "...",
"auth_provider_x509_cert_url": "...",
"client_x509_cert_url": "..."
}
}
然後,您應該可以連線到您的 BigQuery 資料集。
若要在 Superset 中將 CSV 或 Excel 檔案上傳至 BigQuery,您還需要新增 pandas_gbq 函式庫。
目前,Google BigQuery Python SDK 與 gevent 不相容,這是因為 gevent 在 python 核心函式庫上進行了一些動態猴子修補。因此,當您使用 gunicorn 伺服器部署 Superset 時,您必須使用 gevent 以外的工作類型。
Google Sheets
Google Sheets 的 SQL API 非常有限。針對 Google Sheets 建議使用的連接器函式庫為 shillelagh。
將 Superset 連線至 Google Sheets 牽涉幾個步驟。此教學課程包含設定此連線的最新指示。
Hana
建議使用的連接器函式庫為 sqlalchemy-hana。
連線字串的格式如下
hana://{username}:{password}@{host}:{port}
Apache Hive
pyhive 函式庫是透過 SQLAlchemy 連線至 Hive 的建議方式。
預期的連線字串格式如下
hive://hive@{hostname}:{port}/{database}
Hologres
Hologres 是由阿里巴巴雲開發的即時互動式分析服務。它與 PostgreSQL 11 完全相容,並與巨量資料生態系統無縫整合。
Hologres 範例連線參數
- 使用者名稱:您的阿里巴巴雲帳戶的 AccessKey ID。
- 密碼:您的阿里巴巴雲帳戶的 AccessKey 秘密。
- 資料庫主機:Hologres 執行個體的公用端點。
- 資料庫名稱:Hologres 資料庫的名稱。
- Port: Hologres 實例的連接埠號碼。
連線字串如下所示
postgresql+psycopg2://{username}:{password}@{host}:{port}/{database}
IBM DB2
IBM_DB_SA 函式庫提供了 Python / SQLAlchemy 介面,用於連接 IBM 資料伺服器。
以下是建議的連線字串
db2+ibm_db://{username}:{passport}@{hostname}:{port}/{database}
SQLAlchemy 中實作了兩個 DB2 方言版本。如果您連線的 DB2 版本不支援 LIMIT [n] 語法,建議使用以下連線字串,以便使用 SQL Lab:
ibm_db_sa://{username}:{passport}@{hostname}:{port}/{database}
Apache Impala
建議用於 Apache Impala 的連線器函式庫是 impyla。
預期的連線字串格式如下
impala://{hostname}:{port}/{database}
Kusto
建議用於 Kusto 的連線器函式庫是 sqlalchemy-kusto>=2.0.0。
Kusto (sql 方言) 的連線字串如下:
kustosql+https://{cluster_url}/{database}?azure_ad_client_id={azure_ad_client_id}&azure_ad_client_secret={azure_ad_client_secret}&azure_ad_tenant_id={azure_ad_tenant_id}&msi=False
Kusto (kql 方言) 的連線字串如下:
kustokql+https://{cluster_url}/{database}?azure_ad_client_id={azure_ad_client_id}&azure_ad_client_secret={azure_ad_client_secret}&azure_ad_tenant_id={azure_ad_tenant_id}&msi=False
請確保使用者有權限存取和使用所有必要的資料庫/表格/檢視表。
Apache Kylin
建議用於 Apache Kylin 的連線器函式庫是 kylinpy。
預期的連線字串格式如下
kylin://<username>:<password>@<hostname>:<port>/<project>?<param1>=<value1>&<param2>=<value2>
MySQL
建議用於 MySQL 的連線器函式庫是 mysqlclient。
以下是連線字串:
mysql://{username}:{password}@{host}/{database}
主機
- 本機:
localhost或127.0.0.1 - 在 Linux 上執行的 Docker:
172.18.0.1 - 內部部署:IP 位址或主機名稱
- 在 OSX 中執行的 Docker:
docker.for.mac.host.internal連接埠:預設為3306
mysqlclient 的一個問題是,它會無法使用 caching_sha2_password 驗證連線到較新的 MySQL 資料庫,因為用戶端中未包含該外掛程式。在這種情況下,您應該改用 mysql-connector-python
mysql+mysqlconnector://{username}:{password}@{host}/{database}
IBM Netezza Performance Server
nzalchemy 函式庫提供了 Python / SQLAlchemy 介面,用於連線到 IBM Netezza Performance Server (又名 Netezza)。
以下是建議的連線字串
netezza+nzpy://{username}:{password}@{hostname}:{port}/{database}
OceanBase
sqlalchemy-oceanbase 函式庫是透過 SQLAlchemy 連線到 OceanBase 的建議方式。
OceanBase 的連線字串如下:
oceanbase://<User>:<Password>@<Host>:<Port>/<Database>
Ocient DB
建議用於 Ocient 的連線器函式庫是 sqlalchemy-ocient。
安裝 Ocient 驅動程式
pip install sqlalchemy-ocient
連線到 Ocient
Ocient DSN 的格式如下:
ocient://user:password@[host][:port][/database][?param1=value1&...]
Oracle
建議的連線器函式庫是 cx_Oracle。
連線字串的格式如下
oracle://<username>:<password>@<hostname>:<port>
Apache Pinot
建議用於 Apache Pinot 的連線器函式庫是 pinotdb。
預期的連線字串格式如下
pinot+http://<pinot-broker-host>:<pinot-broker-port>/query?controller=http://<pinot-controller-host>:<pinot-controller-port>/``
使用使用者名稱和密碼的預期連線字串格式如下:
pinot://<username>:<password>@<pinot-broker-host>:<pinot-broker-port>/query/sql?controller=http://<pinot-controller-host>:<pinot-controller-port>/verify_ssl=true``
如果您想使用瀏覽視圖或聯結、視窗函數等,請啟用多階段查詢引擎。在建立資料庫連線時,請在「進階」->「其他」->「引擎參數」中新增以下引數
{"connect_args":{"use_multistage_engine":"true"}}
Postgres
請注意,如果您使用的是 docker compose,則 Postgres 連線器函式庫 psycopg2 已隨附於 Superset 中。
Postgres 範例連線參數
- 使用者名稱:使用者名稱
- 密碼:DBPassword
- 資料庫主機:
- 本機:localhost 或 127.0.0.1
- 內部部署:IP 位址或主機名稱
- AWS 端點
- 資料庫名稱:資料庫名稱
- 連接埠:預設 5432
連線字串如下所示
postgresql://{username}:{password}@{host}:{port}/{database}
您可以透過在結尾處新增 ?sslmode=require 來要求 SSL
postgresql://{username}:{password}@{host}:{port}/{database}?sslmode=require
您可以在此文件中的表 31-1中閱讀有關 Postgres 支援的其他 SSL 模式。
有關 PostgreSQL 連線選項的更多資訊,請參閱 SQLAlchemy 文件 和 PostgreSQL 文件。
Presto
pyhive 函式庫是透過 SQLAlchemy 連線到 Presto 的建議方式。
預期的連線字串格式如下
presto://{hostname}:{port}/{database}
您也可以傳入使用者名稱和密碼
presto://{username}:{password}@{hostname}:{port}/{database}
以下是包含值的連線字串範例
presto://datascientist:securepassword@presto.example.com:8080/hive
預設情況下,Superset 在查詢資料來源時會假設使用最新版本的 Presto。如果您使用的是較舊版本的 Presto,您可以在額外參數中進行設定
{
"version": "0.123"
}
SSL 安全額外新增 JSON 設定至額外連線資訊。
{
"connect_args":
{"protocol": "https",
"requests_kwargs":{"verify":false}
}
}
RisingWave
建議用於 RisingWave 的連線器函式庫是 sqlalchemy-risingwave。
預期的連線字串格式如下
risingwave://root@{hostname}:{port}/{database}?sslmode=disable
Rockset
Rockset 的連線字串如下:
rockset://{api key}:@{api server}
從 Rockset 主控台取得您的 API 金鑰。從 API 參考中找到您的 API 伺服器。省略 URL 的 https:// 部分。
若要鎖定特定的虛擬執行個體,請使用以下 URI 格式
rockset://{api key}:@{api server}/{VI ID}
如需更完整的指示,我們建議您參閱Rockset 文件。
Snowflake
安裝 Snowflake 驅動程式
請依照這裡的步驟,了解如何在透過 docker compose 本機設定 Superset 時安裝新的資料庫驅動程式。
echo "snowflake-sqlalchemy" >> ./docker/requirements-local.txt
建議用於 Snowflake 的連線器函式庫是 snowflake-sqlalchemy。
Snowflake 的連線字串如下:
snowflake://{user}:{password}@{account}.{region}/{database}?role={role}&warehouse={warehouse}
綱要不是連線字串中的必要項目,因為它是依表格/查詢定義的。如果已為使用者定義預設值,則可以省略角色和倉儲,例如:
snowflake://{user}:{password}@{account}.{region}/{database}
請確保使用者有權限存取和使用所有必要的資料庫/綱要/表格/檢視表/倉儲,因為 Snowflake SQLAlchemy 引擎預設不會在引擎建立期間測試使用者/角色權限。但是,當在「建立或編輯資料庫」對話方塊中按下「測試連線」按鈕時,會透過在引擎建立期間將「validate_default_parameters": True 傳遞至 connect() 方法來驗證使用者/角色憑證。如果使用者/角色未獲授權存取資料庫,則會在 Superset 日誌中記錄錯誤。
如果您想使用 金鑰對驗證連線 Snowflake。請確保您擁有金鑰對,並且公鑰已在 Snowflake 中註冊。若要使用金鑰對驗證連線 Snowflake,您需要在「安全額外」欄位中新增以下參數。
請注意,您需要將多行私鑰內容合併為一行,並在每行之間插入 \n
{
"auth_method": "keypair",
"auth_params": {
"privatekey_body": "-----BEGIN ENCRYPTED PRIVATE KEY-----\n...\n...\n-----END ENCRYPTED PRIVATE KEY-----",
"privatekey_pass":"Your Private Key Password"
}
}
如果您的私鑰儲存在伺服器上,您可以在參數中使用「privatekey_path」取代「privatekey_body」。
{
"auth_method": "keypair",
"auth_params": {
"privatekey_path":"Your Private Key Path",
"privatekey_pass":"Your Private Key Password"
}
}
Apache Solr
sqlalchemy-solr 函式庫提供了 Python / SQLAlchemy 介面,用於連線到 Apache Solr。
Solr 的連線字串如下:
solr://{username}:{password}@{host}:{port}/{server_path}/{collection}[/?use_ssl=true|false]
Apache Spark SQL
建議用於 Apache Spark SQL 的連線器函式庫 pyhive。
預期的連線字串格式如下
hive://hive@{hostname}:{port}/{database}
SQL Server
建議用於 SQL Server 的連線器函式庫是 pymssql。
SQL Server 的連線字串如下:
mssql+pymssql://<Username>:<Password>@<Host>:<Port-default:1433>/<Database Name>/?Encrypt=yes
也可以使用 pyodbc 和參數 odbc_connect 來連線
SQL Server 的連線字串如下:
mssql+pyodbc:///?odbc_connect=Driver%3D%7BODBC+Driver+17+for+SQL+Server%7D%3BServer%3Dtcp%3A%3Cmy_server%3E%2C1433%3BDatabase%3Dmy_database%3BUid%3Dmy_user_name%3BPwd%3Dmy_password%3BEncrypt%3Dyes%3BConnection+Timeout%3D30
StarRocks
建議使用 sqlalchemy-starrocks 函式庫,透過 SQLAlchemy 連接 StarRocks。
您需要以下設定值來構成連線字串
- 使用者:使用者名稱
- 密碼:DBPassword
- 主機(Host):StarRocks FE 主機
- 目錄:目錄名稱
- 資料庫:資料庫名稱
- 埠號(Port):StarRocks FE 埠號
以下是連線字串的樣子
starrocks://<User>:<Password>@<Host>:<Port>/<Catalog>.<Database>
StarRocks 維護其 Superset 文件,請參考此處。
Teradata
建議的連接器函式庫是 teradatasqlalchemy。
Teradata 的連線字串如下所示
teradatasql://{user}:{password}@{host}
ODBC 驅動程式
還有一個較舊的連接器,名為 sqlalchemy-teradata,它需要安裝 ODBC 驅動程式。Teradata ODBC 驅動程式可在此處取得: https://downloads.teradata.com/download/connectivity/odbc-driver/linux
以下是需要的環境變數
export ODBCINI=/.../teradata/client/ODBC_64/odbc.ini
export ODBCINST=/.../teradata/client/ODBC_64/odbcinst.ini
我們建議使用第一個函式庫,因為它不需 ODBC 驅動程式,而且更新更頻繁。
TimescaleDB
TimescaleDB 是用於時間序列和分析的開源關聯式資料庫,用於建構強大的資料密集型應用程式。TimescaleDB 是 PostgreSQL 的擴充功能,您可以使用標準 PostgreSQL 連接器函式庫 psycopg2 連接資料庫。
如果您使用 Docker Compose,psycopg2 會隨 Superset 一起提供。
TimescaleDB 範例連線參數
- 使用者名稱:使用者
- 密碼:密碼
- 資料庫主機:
- 本機:localhost 或 127.0.0.1
- 內部部署:IP 位址或主機名稱
- 針對 Timescale Cloud 服務:主機名稱
- 針對 Managed Service for TimescaleDB 服務:主機名稱
- 資料庫名稱:資料庫名稱
- 埠號:預設 5432 或服務的埠號
連線字串如下所示
postgresql://{username}:{password}@{host}:{port}/{database name}
您可以透過在結尾新增 ?sslmode=require 來要求 SSL(例如,如果您使用 Timescale Cloud 的話)
postgresql://{username}:{password}@{host}:{port}/{database name}?sslmode=require
Trino
支援 Trino 352 及更高版本
連線字串
連線字串格式如下
trino://{username}:{password}@{hostname}:{port}/{catalog}
如果您在本地電腦上使用 Docker 執行 Trino,請使用以下連線 URL
trino://trino@host.docker.internal:8080
驗證
1. 基本驗證
您可以在連線字串中或在 進階 / 安全性 的 Secure Extra 欄位中提供 username/password
-
在連線字串中
trino://{username}:{password}@{hostname}:{port}/{catalog} -
在
Secure Extra欄位中{
"auth_method": "basic",
"auth_params": {
"username": "<username>",
"password": "<password>"
}
}
注意:如果兩者都提供,Secure Extra 始終具有較高的優先順序。
2. Kerberos 驗證
在 Secure Extra 欄位中,如下列範例設定
{
"auth_method": "kerberos",
"auth_params": {
"service_name": "superset",
"config": "/path/to/krb5.config",
...
}
}
auth_params 中的所有欄位都會直接傳遞至 KerberosAuthentication 類別。
注意:Kerberos 驗證需要在本機安裝 trino-python-client,並使用 all 或 kerberos 選用功能,也就是分別安裝 trino[all] 或 trino[kerberos]。
3. 憑證驗證
在 Secure Extra 欄位中,如下列範例設定
{
"auth_method": "certificate",
"auth_params": {
"cert": "/path/to/cert.pem",
"key": "/path/to/key.pem"
}
}
auth_params 中的所有欄位都會直接傳遞至 CertificateAuthentication 類別。
4. JWT 驗證
設定 auth_method 並在 Secure Extra 欄位中提供權杖
{
"auth_method": "jwt",
"auth_params": {
"token": "<your-jwt-token>"
}
}
5. 自訂驗證
若要使用自訂驗證,首先您需要在 Superset 設定檔中的 ALLOWED_EXTRA_AUTHENTICATIONS 允許清單中新增它
from your.module import AuthClass
from another.extra import auth_method
ALLOWED_EXTRA_AUTHENTICATIONS: Dict[str, Dict[str, Callable[..., Any]]] = {
"trino": {
"custom_auth": AuthClass,
"another_auth_method": auth_method,
},
}
然後在 Secure Extra 欄位中
{
"auth_method": "custom_auth",
"auth_params": {
...
}
}
您也可以透過提供對您的 trino.auth.Authentication 類別或工廠函數 (返回 Authentication 執行個體) 的參考至 auth_method 來使用自訂驗證。
auth_params 中的所有欄位都會直接傳遞至您的類別/函數。
參考資料:
Vertica
建議的連接器函式庫是 sqlalchemy-vertica-python。Vertica 連線參數如下
- 使用者名稱: 使用者名稱
- 密碼: 資料庫密碼
- 資料庫主機
- 針對本機主機:localhost 或 127.0.0.1
- 針對內部部署:IP 位址或主機名稱
- 針對雲端:IP 位址或主機名稱
- 資料庫名稱: 資料庫名稱
- 埠號: 預設 5433
連線字串的格式如下
vertica+vertica_python://{username}:{password}@{host}/{database}
其他參數
- 負載平衡器 - 備份主機
YugabyteDB
YugabyteDB 是建構於 PostgreSQL 之上的分散式 SQL 資料庫。
請注意,如果您使用的是 docker compose,則 Postgres 連線器函式庫 psycopg2 已隨附於 Superset 中。
連線字串如下所示
postgresql://{username}:{password}@{host}:{port}/{database}
透過 UI 連接
以下是關於如何利用新 DB 連線 UI 的文件。這將提供管理員增強想要連線到新資料庫的使用者的 UX 的能力。
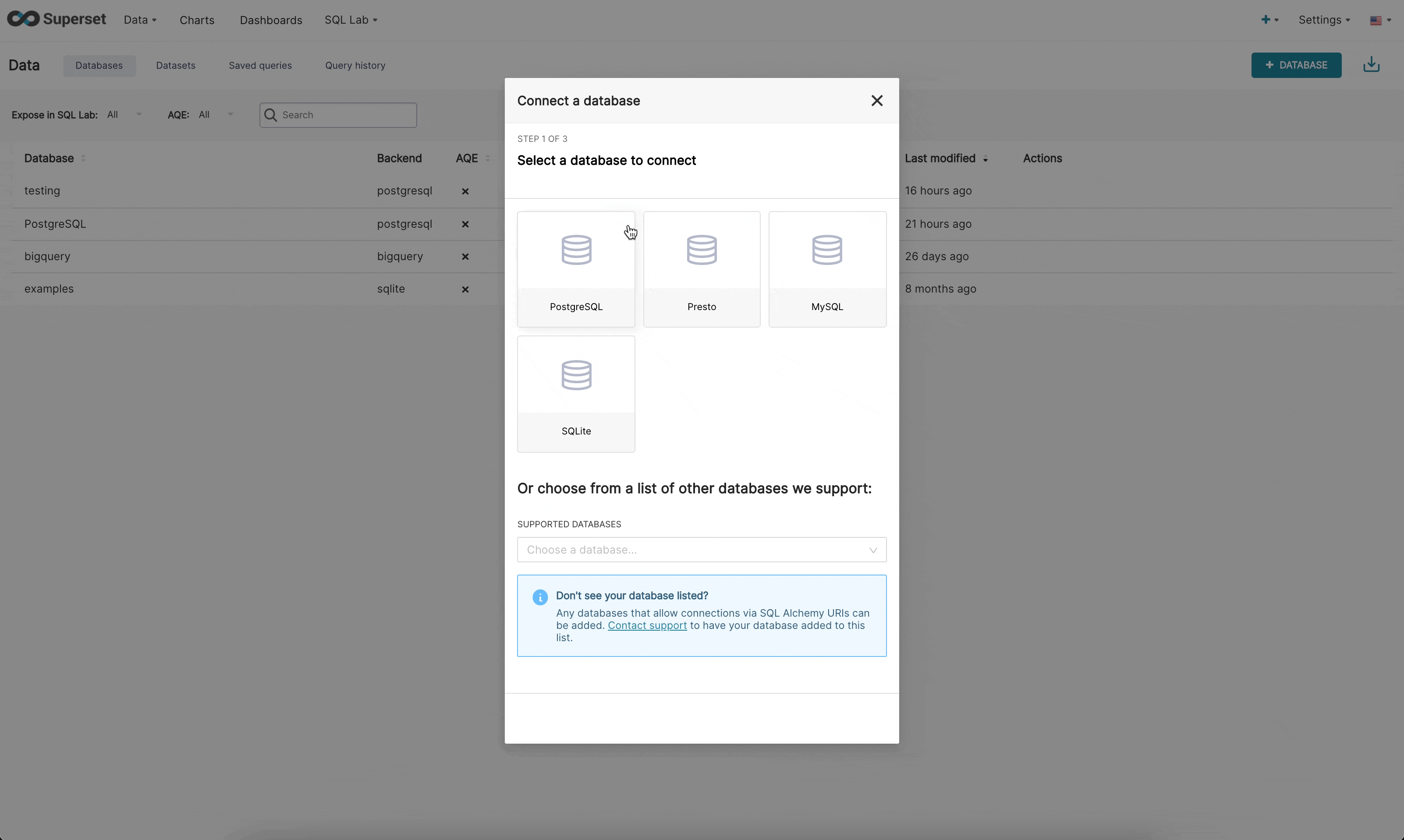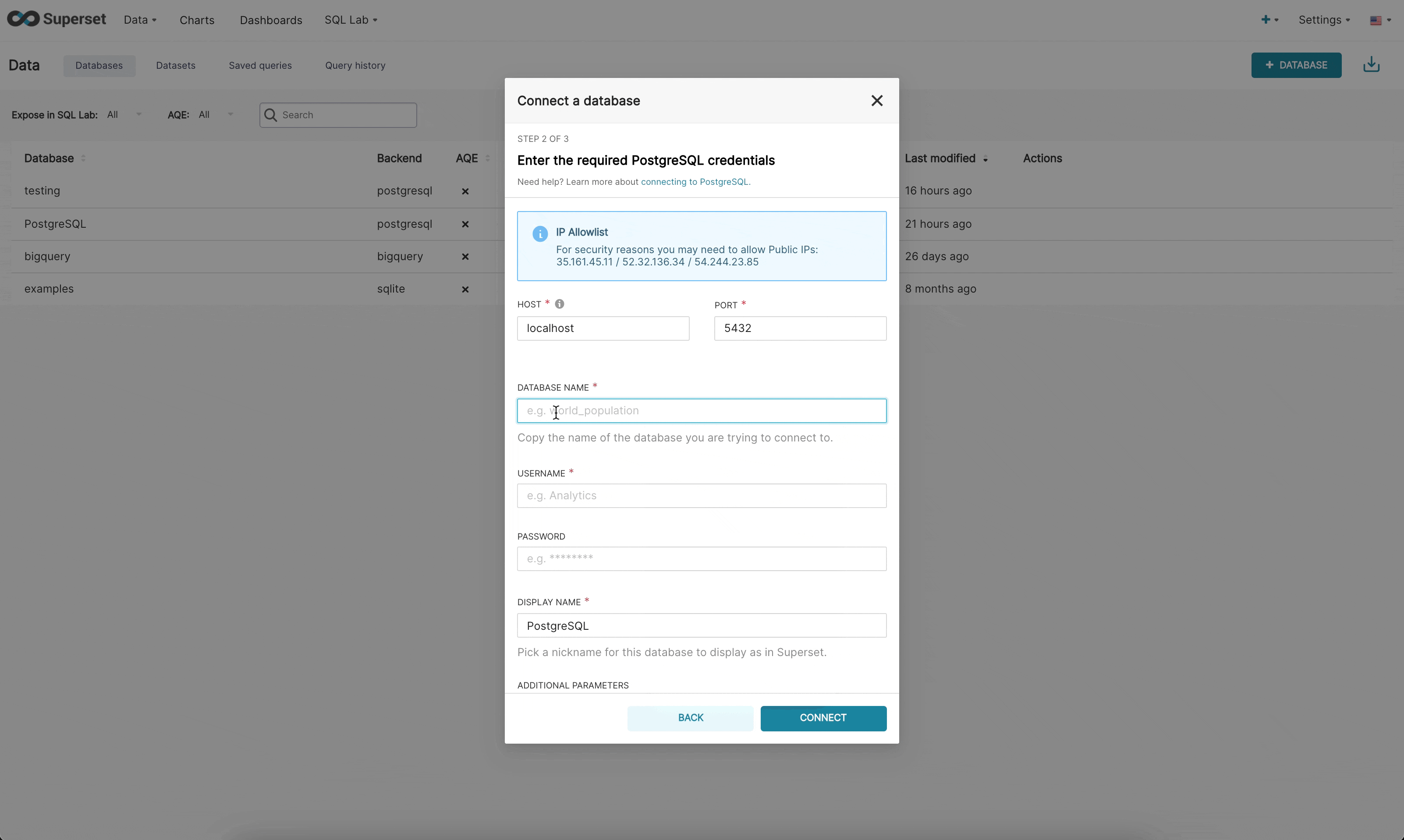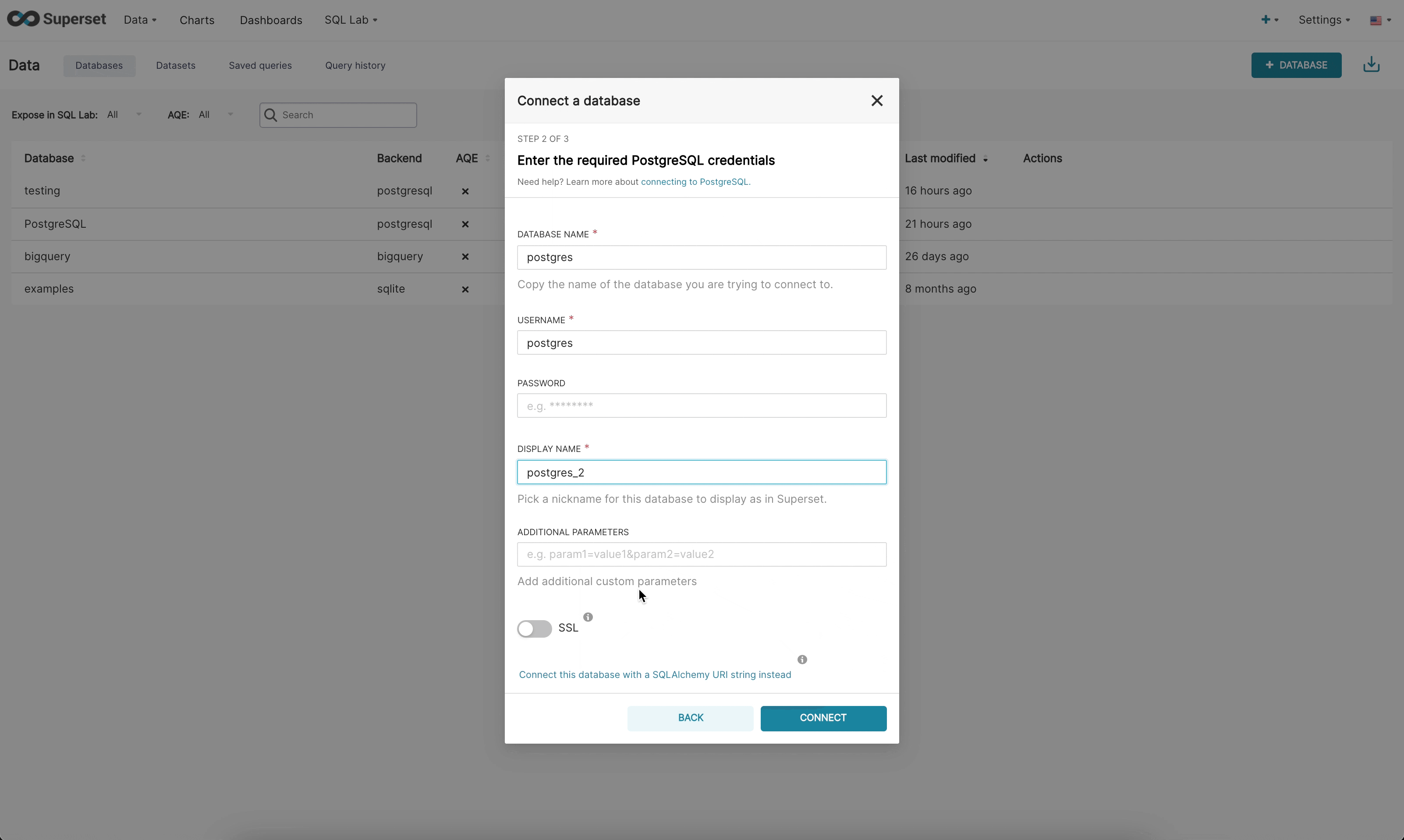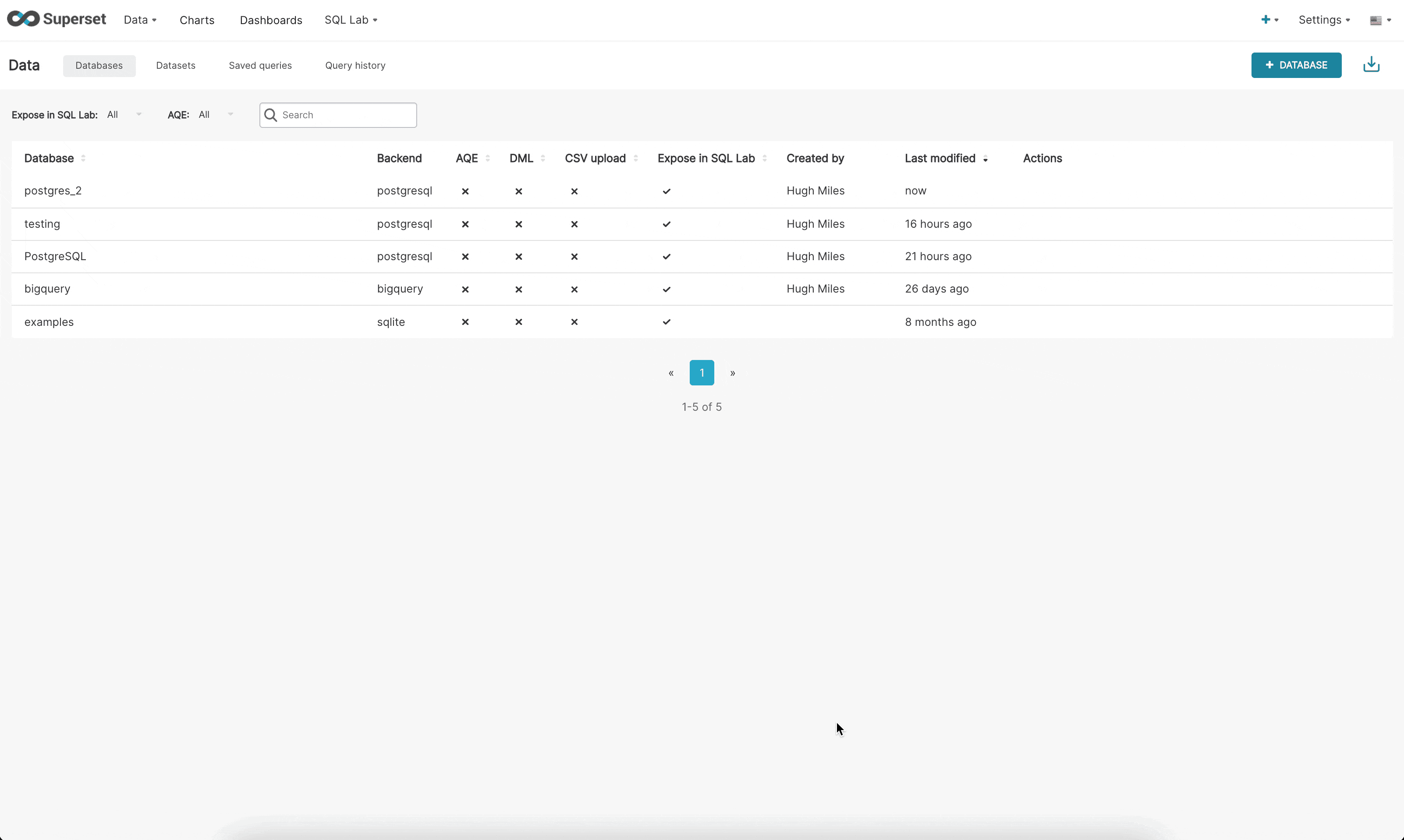
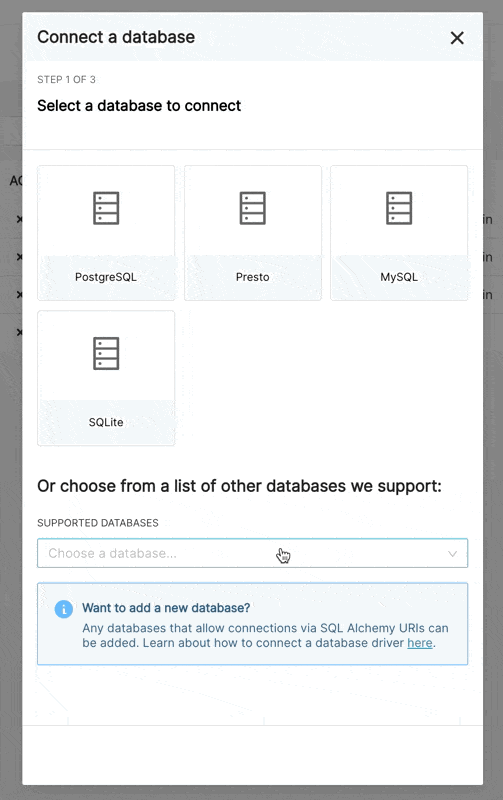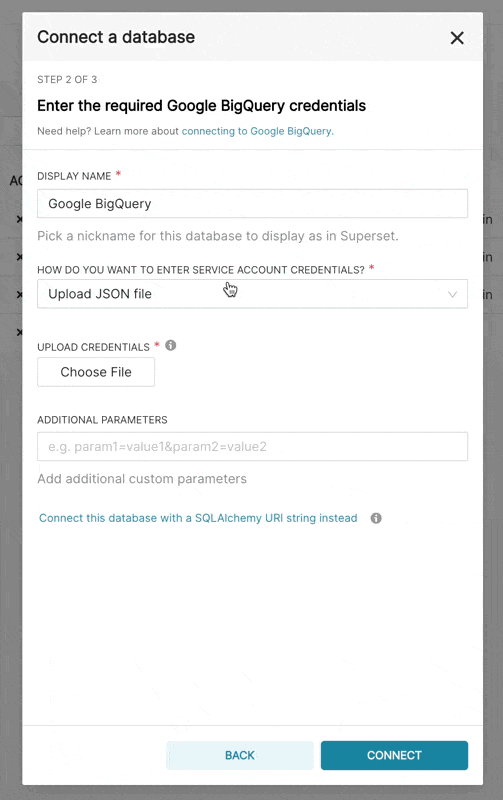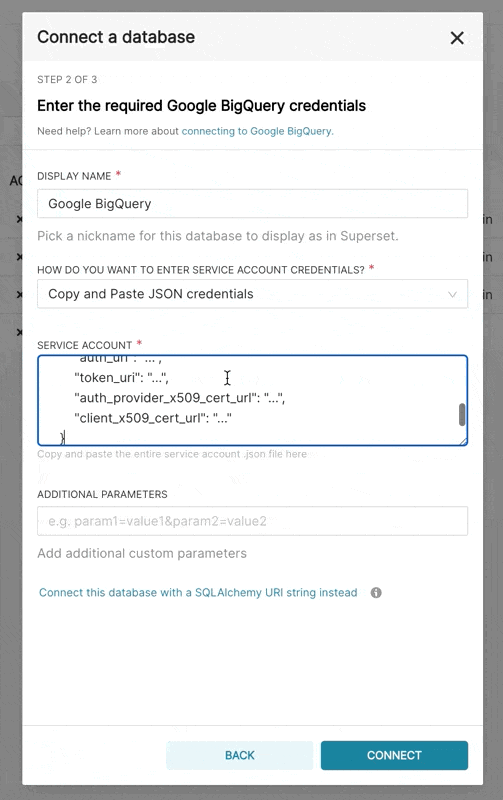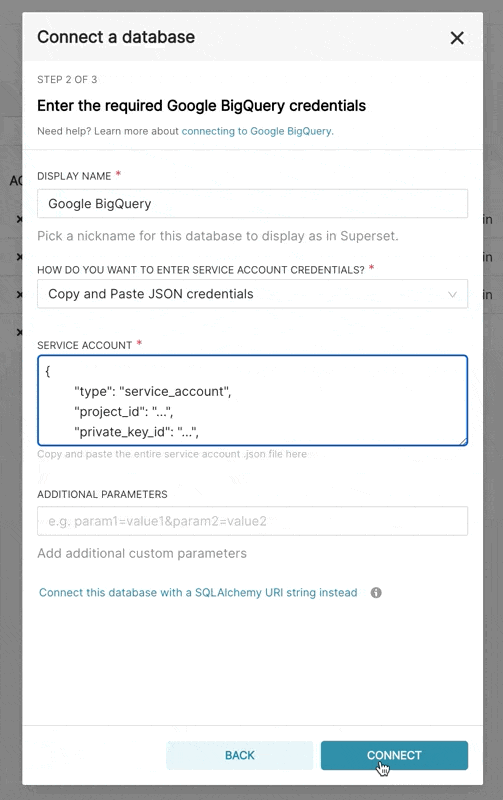
在新 UI 中連線到資料庫時,現在有 3 個步驟
步驟 1:首先,管理員必須告知 Superset 他們想要連線到哪個引擎。此頁面由 /available 端點提供支援,該端點會提取目前安裝在您環境中的引擎,以便只顯示支援的資料庫。
步驟 2:接下來,會提示管理員輸入資料庫特定的參數。根據是否有可供該特定引擎使用的動態表單,管理員將看到新的自訂表單或舊版的 SQLAlchemy 表單。我們目前已針對 (Redshift、MySQL、Postgres 和 BigQuery) 建構動態表單。新表單會提示使用者輸入連線所需的參數 (例如,使用者名稱、密碼、主機、埠號等),並立即提供錯誤回饋。
步驟 3:最後,一旦管理員使用動態表單連線到他們的 DB,他們就有機會更新任何選用的進階設定。
我們希望此功能將有助於消除使用者進入應用程式並開始建立資料集的巨大瓶頸。
如何設定偏好的資料庫選項和映像
我們新增了一個新的設定選項,管理員可以在其中依順序定義他們偏好的資料庫
# A list of preferred databases, in order. These databases will be
# displayed prominently in the "Add Database" dialog. You should
# use the "engine_name" attribute of the corresponding DB engine spec
# in `superset/db_engine_specs/`.
PREFERRED_DATABASES: list[str] = [
"PostgreSQL",
"Presto",
"MySQL",
"SQLite",
]
出於著作權原因,每個資料庫的標誌都不會隨 Superset 一起發布。
設定映像
- 若要設定偏好資料庫的映像,管理員必須在
superset_text.yml檔案中使用引擎和映像位置建立對應。映像可以本機託管在您的靜態/檔案目錄內,或在線上 (例如 S3)
DB_IMAGES:
postgresql: "path/to/image/postgres.jpg"
bigquery: "path/to/s3bucket/bigquery.jpg"
snowflake: "path/to/image/snowflake.jpg"
如何將新的資料庫引擎新增至可用的端點
目前新的模式支援以下資料庫
- Postgres
- Redshift
- MySQL
- BigQuery
當使用者選擇不在清單中的資料庫時,他們將看到舊的對話方塊,要求提供 SQLAlchemy URI。新的資料庫可以逐步新增至新的流程。為了支援豐富的設定,DB 引擎規格需要具有以下屬性
parameters_schema:定義設定資料庫所需參數的 Marshmallow 結構描述。對於 Postgres,這包括使用者名稱、密碼、主機、埠號等。(請參閱)。default_driver:DB 引擎規格建議驅動程式的名稱。許多 SQLAlchemy 方言支援多個驅動程式,但通常有一個是官方建議。對於 Postgres,我們使用「psycopg2」。sqlalchemy_uri_placeholder:一個字串,可在使用者想要直接輸入 URI 時提供協助。encryption_parameters:使用者選擇加密連線時用於建構 URI 的參數。對於 Postgres,這是{"sslmode": "require"}。
此外,DB 引擎規格必須實作這些類別方法
build_sqlalchemy_uri(cls, parameters, encrypted_extra):此方法會接收不同的參數並從它們建構 URI。get_parameters_from_uri(cls, uri, encrypted_extra):此方法會執行相反的操作,從給定的 URI 擷取參數。validate_parameters(cls, parameters):此方法用於表單的onBlur驗證。它應該返回一個SupersetError清單,指出哪些參數遺失,以及哪些參數絕對不正確 (範例)。
對於像 MySQL 和 Postgres 這種使用 engine+driver://user:password@host:port/dbname 標準格式的資料庫,您只需要將 BasicParametersMixin 新增至 DB 引擎規格,然後定義參數 2-4 (parameters_schema 已存在於 mixin 中)。
對於其他資料庫,您需要自行實作這些方法。BigQuery DB 引擎規格是說明如何執行此操作的好例子。
額外的資料庫設定
更深入的 SQLAlchemy 整合
可以使用 SQLAlchemy 公開的參數來調整資料庫連線資訊。在 [資料庫編輯] 檢視中,您可以將 [額外] 欄位編輯為 JSON Blob。
這個 JSON 字串包含額外的設定元素。engine_params 物件會解壓縮到 sqlalchemy.create_engine 呼叫中,而 metadata_params 會解壓縮到 sqlalchemy.MetaData 呼叫中。如需詳細資訊,請參閱 SQLAlchemy 文件。
結構描述
像 Postgres 和 Redshift 這樣的資料庫會使用 schema(綱要) 作為 database(資料庫) 之上的邏輯實體。為了讓 Superset 連接到特定的 schema,您可以在 編輯表格 表單中設定 schema 參數(來源 > 表格 > 編輯記錄)。
SQLAlchemy 連線的外部密碼儲存
Superset 可以設定為使用外部儲存空間來存放資料庫密碼。如果您正在執行自訂的密碼分發框架,而且不希望將密碼儲存在 Superset 的中繼資料庫中,這會很有用。
範例:撰寫一個函式,該函式接受一個 sqla.engine.url 類型的單一引數,並返回指定連線字串的密碼。然後在您的設定檔中設定 SQLALCHEMY_CUSTOM_PASSWORD_STORE,使其指向該函式。
def example_lookup_password(url):
secret = <<get password from external framework>>
return 'secret'
SQLALCHEMY_CUSTOM_PASSWORD_STORE = example_lookup_password
一種常見的模式是使用環境變數來提供密碼。 SQLALCHEMY_CUSTOM_PASSWORD_STORE 也可用於此目的。
def example_password_as_env_var(url):
# assuming the uri looks like
# mysql://localhost?superset_user:{SUPERSET_PASSWORD}
return url.password.format(**os.environ)
SQLALCHEMY_CUSTOM_PASSWORD_STORE = example_password_as_env_var
資料庫的 SSL 存取
您可以使用 編輯資料庫 表單中的 Extra 欄位來設定 SSL。
{
"metadata_params": {},
"engine_params": {
"connect_args":{
"sslmode":"require",
"sslrootcert": "/path/to/my/pem"
}
}
}
其他
跨資料庫查詢
Superset 提供了一個實驗性功能,可供跨不同資料庫進行查詢。這是透過一個名為「Superset 中繼資料庫」的特殊資料庫完成的,該資料庫使用「superset://」SQLAlchemy URI。使用此資料庫時,可以使用以下語法查詢任何已設定資料庫中的任何表格
SELECT * FROM "database name.[[catalog.].schema].table name";
例如
SELECT * FROM "examples.birth_names";
允許使用空格,但名稱中的句點必須替換為 %2E。例如
SELECT * FROM "Superset meta database.examples%2Ebirth_names";
上面的查詢會傳回與 SELECT * FROM "examples.birth_names" 相同的列,並且也顯示中繼資料庫可以查詢任何表格(包括它自己!)的表格。
注意事項
在啟用此功能之前,您應該考慮一些事項。首先,中繼資料庫會對查詢的表格強制執行權限,因此使用者應該只能透過資料庫存取他們原本有權存取的表格。儘管如此,中繼資料庫是一個潛在攻擊的新介面,而且錯誤可能會讓使用者看到他們不應該看到的資料。
其次,有一些效能方面的考量。中繼資料庫會將任何篩選、排序和限制推送到基礎資料庫,但任何聚合和聯結都會在執行查詢的程序中的記憶體中進行。因此,建議在非同步模式下執行資料庫,以便查詢在 Celery 工作程式中執行,而不是在 Web 工作程式中執行。此外,還可以指定從基礎資料庫返回的列數的硬性限制。
啟用中繼資料庫
若要啟用 Superset 中繼資料庫,您首先需要將 ENABLE_SUPERSET_META_DB 功能標記設定為 true。然後,新增一個類型為「Superset 中繼資料庫」且 SQLAlchemy URI 為「superset://」的新資料庫。
如果您在中繼資料庫中啟用 DML,使用者將能夠在基礎資料庫上執行 DML 查詢,**只要也在這些資料庫中啟用 DML**。這允許使用者執行跨資料庫移動資料的查詢。
其次,您可能想要變更 SUPERSET_META_DB_LIMIT 的值。預設值為 1000,並定義在執行任何聚合和聯結之前,從每個資料庫讀取的列數。如果只有小型表格,您也可以將此值設定為 None。
此外,您可能想要限制中繼資料庫可以存取的資料庫。這可以在資料庫設定中的「進階」->「其他」->「引擎參數」下完成,並新增
{"allowed_dbs":["Google Sheets","examples"]}